이 글은 오래된 전에 작성된 글입니다. 따라서 최신 버전의 기술에 알맞지 않거나 오류를 유발할 수 있습니다.
저자는 이 글에 대한 질문을 받지 않을 것입니다. 하지만 이 글이 리뉴얼 되면 이 글에 대한 질문을 하거나
토론을 할 수도 있습니다.
패턴... 참 좋은 단어 입니다. 말 그대로 주어진 틀에 맞춘다는 것이지요. Microsoft 가 자사의 기술을 이용하는데 적용하라고 제시하는 Pattern & Practice 씨리즈의 글들 역시 일정 패턴에 맞추어 어플리케이션을 설계하고 구현하고 배포하라는 것을 가이드 하고 있습니다. 객체 지향 설계/구현에서 많이 인용되며 사용되는 디자인 패턴 역시 그러합니다.
Microsoft 기술 기반의 어플리케이션에서 데이터베이스를 액세스할 때 작성하는 코드 역시 권장되는 패턴이 있습니다. 이는 VBScript, VB 6.0 등의 Unmanaged Code에서 사용되는 ADO에도 적용되며, 닷넷 기반의 코드를 작성할 때도 역시 적용되는 코딩 패턴입니다. 하지만 많은 개발자들이 이것을 간과하는 경우가 많습니다. 물론, 코딩 패턴은 말 그대로 패턴일 뿐이지 절대적인 진리는 아닙니다. 단순히 코드 패턴을 암기해서 기계적으로 코드를 작성하는 것보다 왜 그런 패턴을 권장하는지 아는 것이 중요하다고 할 수 있지요. 그래야만 해당 코딩 패턴을 적용해야 할지, 아니면 그것을 응용한 다른 코드를 작성해야 할지, 패턴을 무시해야 할지를 결정할 수 있으니까요.
필자가 걱정하는 것은 이 글로 인해, 무조건 이렇게 코딩을 해야 한다든가 이것이 진리라든가 등등 독자들이 잘못된 인식을 갖을까 두렵습니다만, 잘못된 아니 잘못되었다기보다는 효율적이지 않은, 성능에 도움되지 않는 데이터 액세스 코드를 작성하는 일들이 줄어 들었으면 하는 바램에서 ADO.NET 코딩 패턴 씨리즈의 포스트를 작성해 보려고 합니다.
이 글에서 비효율적인 데이터 액세스 코드들을 지적할 것이고 왜 비효율적인가를 설명할 겁니다. 그리고 권장되는 데이터 액세스 코드 패턴을 제시할 겁니다. 이 권장 사항은 필자의 권장 사항임을 강조합니다. 물론 이들 중에는 마이크로소프트의 권장 사항이기도 한 것도 있습니다만 구체적으로 어느 사이트 혹은 문서에서 마이크로소프트가 권장하고 있는가를 모두 구별해 드릴 수는 없습니다(귀차니즘이 물밀듯이 밀려와서... 언젠가 저는 이 게으름으로 망할 듯...). 필자가 권고하는 사항을 받아들이는 것은 순전히 독자의 몫입니다. 다만 제가 얼토당토 않은 제안을 하지 않는다는 점과 여러 자료, 예제들을 기반으로 필자의 경험과 테스트를 바탕으로 심사숙고(?)해서 드리는 제안이라는 점만을 알아 주시면 감사하겠습니다(책임 회피의 냄새가 풀풀 나죠? -_-;). 생산적이고 건설적인 토론이나 필자의 잘못된 지식을 지적해 주시는 것은 항상 환영하지만, 소모적이고 우격다짐식의 비판이나 논쟁은 사양합니다.
참고로, 이 씨리즈의 글들은 모두 ADO.NET 기반, 즉 닷넷 기반에서의 코딩 패턴에 대해 다룹니다. 닷넷 이전 unmanaged 코드에 대한 코딩 패턴은 필자가 2001년 9월 월간 마이크로소프트에 기고했었던 "제대로 알아보는 ADO 코딩 패턴" 이란 글을 참조해 주십시오 (사이트에서 원문을 보실 수 없으며 PDF를 다운로드 해야 합니다. 500원이라는 돈이 들죠... -_-;; 오해는 하지 마시길...).
Use Parameterized Query
데이터베이스 기반의 어플리케이션이 성능이 기대보다 못 미치는 경우가 많이 발생하곤 한다. 대부분 데이터베이스 설계가 잘 못되었거나 인덱스의 부적절한 사용, 데이터베이스 튜닝 부족 등을 이유로 꼽을 수 있다. 이러한 요인 외에도 잘못된, 아니 잘못되었다기보다는 효율적이지 못한 데이터 액세스 코드로 인해 데이터베이스의 부하가 증가하는 경우가 많다. 데이터베이스에 부하가 증가한다는 것은 곧 성능적인 손해가 올 수 있음을 의미한다.
Non-parameterized Query
대표적으로 비효율적인 데이터 액세스 코드는 매개변수를 사용하지 않는 쿼리 문장을 사용하는 것이다. 예를 들어 설명하는 것이 가장 빠를 것 같다. 다음 코드가 필자가 말하는 '비효율적인 코드'가 되겠다.
private const string _ConnectionString = "SERVER=(local);UID=yourid;PWD=yourpwd;Database=Northwind";
private static DataSet NonParameterizedQuery1(string customerID, DateTime beginDate, DateTime endDate)
{
// 문자열 연산으로 SQL 문장을 만든다. 좋지 못하다.
string query = "SELECT * FROM Orders WHERE customerID = '" + customerID +
"' AND OrderDate >= '" + beginDate.ToString("yyyy-MM-dd") +
"' AND OrderDate <= '" + endDate.ToString("yyyy-MM-dd") + "'";
SqlDataAdapter adapter = new SqlDataAdapter(query, _ConnectionString);
DataSet ds = new DataSet();
adapter.Fill(ds);
return ds;
}
리스트1. 매개변수를 사용하지 않는 데이터 액세스 예제1
리스트1은 Northwind 데이터베이스의 Orders 테이블에서 주어진 주문자(customerID)에 대해 주어진 기간(beginDate와 endDate 사이)에서 주문한 내역을 조회하는 코드이다. 얼핏 보면 아무런 문제가 없어 보이는 코드이다. 게다가 매우 잘 작동한다. 하지만 이 코드는 비효율적으로 데이터 액세스를 수행하고 있다. 필자가 구라를 치지 않는다는 증거를 이제 살펴보자.
SQL Compilation & Query Plan
SQL Server(다른 데이터베이스도 마찬가지라고 생각한다)는 SQL 쿼리 문장이 주어지면 이것을 파싱하고 컴파일하여 실행계획(query plan)을 생성한다. 그리고 이 실행 계획을 다음에 재사용하기 위해 캐시하여 다음에 동일한 쿼리를 수행할 때 SQL 문장을 다시 컴파일하고 실행 계획을 세우는 일을 줄인다. 뭐... 당연히 그래야 할 것이다. 그런데... SQL Server가 캐시된 실행 계획을 찾는데 있어서 매우 똑똑하지 못하다는 것이다 (사실 상당히 똑똑한 편인데도 불구하고 사람의 관점에서 보면 똑똑하지 않은 것 처럼 보인다). 리스트1의 NonParameterizedQuery1 메쏘드를 다음과 같이 2회 호출한다고 가정해 보자.
string customerID = "VINET";
DateTime beginDate = new DateTime(1996, 1, 1);
DateTime endDate = new DateTime(1996, 1, 31);
DataSet ds = NonParameterizedQuery1(customerID, beginDate, endDate);
customerID = "VINET";
beginDate = new DateTime(1996, 2, 1);
endDate = new DateTime(1996, 2, 29);
ds = NonParameterizedQuery1(customerID, beginDate, endDate);
위 두 호출은 결과적으로 SQL Server에 대해 다음 두 문장을 수행하는 결과를 낳는다. 뭐 코드가 뻔하니깐 당연하겠지...
SELECT * FROM Orders WHERE customerID = 'VINET' AND OrderDate >= '1996-01-01'
AND OrderDate <= '1996-01-31'
SELECT * FROM Orders WHERE customerID = 'VINET' AND OrderDate >= '1996-02-01'
AND OrderDate <= '1996-02-29'
우리가 보기엔 두 쿼리는 전혀 다르지 않아 보인다. WHERE 절에 조회 조건으로 주어진 조회 기간 '매개변수'의 값만이 다른 것이 아닌가? 우리에겐 같아 보이는 두 쿼리가 SQL Server에겐 다르게 보인다는 것이다. 그래서 SQL Server는 이 두 쿼리를 다른 것으로 간주하고 SQL 컴파일과 실행 계획을 매번 세우게 된다. 정말로 SQL Server가 컴파일을 매번 수행하는지 알아보고 싶다면 리스트1의 NonParameterizedQuery1 메쏘드를 매개변수를 매번 다르게 하여 호출하면서 성능 모니터를 통해 SQL Server의 SQL Compilation/sec 성능 카운터 항목을 살펴보기 바란다. 매개변수를 쓰지 않는 리스트1의 코드는 높은 SQL 컴파일 회수를 나타낼 것이다.
이제 왜 매개변수를 쓰지 않는 쿼리를 사용하면 효율이 떨어지는지에 대한 첫 번째 해답이 될 것이다.
String Concatenation
리스트1의 코드에서 원하는 SQL 쿼리 문장을 만들기 위해서 문자열들을 더하는(concatenate) 연산을 하고 있음을 알 수 있다. 문자열을 더하는 것이 좋지 않다는 말을 어디서 들어보지 않았는가? 그렇다. 문자열 연산은 좋지 못하다. 피할 수 있다면 피하는 것이 좋다. 그래서 문자열 연산 대신 StringBuilder를 사용하여 다음과 같은 코드를 생각해 볼 수 있겠다.
private static DataSet NonParameterizedQuery2(string customerID, DateTime beginDate, DateTime endDate)
{
// StringBuilder로 SQL 문장을 만든다. 가장 좋지 못하다.
StringBuilder sb = new StringBuilder();
sb.Append("SELECT * FROM Orders WHERE customerID = '");
sb.Append(customerID);
sb.Append("' AND OrderDate >= '");
sb.Append(beginDate.ToString("yyyy-MM-dd"));
sb.Append("' AND OrderDate <= '");
sb.Append(endDate.ToString("yyyy-MM-dd"));
sb.Append("'");
SqlDataAdapter adapter = new SqlDataAdapter(sb.ToString(), _ConnectionString);
DataSet ds = new DataSet();
adapter.Fill(ds);
return ds;
}
리스트2. 매개변수를 사용하지 않으면서 StringBuilder까지 쓰는 예제 코드. 대략 가장 좋지 않다.
뭐 좋은 의도로 StringBuilder를 썼겠지만, 결과적으로는 더욱 좋지 못하다. 왜 StringBuilder를 쓰면 더 안 좋아지는 가에 대해서는 필자의 "StringBuilder에 대한 진실 혹은 거짓말" 씨리즈 글들을 살펴보는 것이 좋겠다.
리스트1과 같이 문자열 연산을 쓰거나 리스트2와 같이 StringBuilder를 사용하는 것은 데이터베이스 서버에 영향을 준다기 보다는 웹 서버나 COM+가 수행되는 어플리케이션 서버의 가비지 컬렉션 효율을 떨어뜨리는 원인이 되겠다. 암튼 비효율은 비효율이니까....
Recommendation
Use Parameterized Query
잔뜩 코드들을 비판했으면 대안을 제시해야 할 것 아닌가? 대안은 매개변수를 사용하는 쿼리를 사용하는 것이다. 즉, 쿼리에 변하는 변수 부분을 매개변수로 처리하면 된다. 말로 설명하기 영 까칠하므로 예제 코드를 보자.
private static DataSet ParameterizedQuery(string customerID, DateTime beginDate, DateTime endDate)
{
// 문자열 상수만을 이용하고 있다. 가장 좋다.
string query = "SELECT * FROM Orders WHERE customerID = @customerID " +
"AND OrderDate >= @beginDate " +
"AND OrderDate <= @endDate";
SqlConnection conn = new SqlConnection(_ConnectionString);
SqlCommand cmd = new SqlCommand(query, conn);
SqlDataAdapter adapter = new SqlDataAdapter(cmd);
DataSet ds = new DataSet();
cmd.Parameters.Add("@customerID", SqlDbType.NChar, 5).Value = customerID;
cmd.Parameters.Add("@beginDate", SqlDbType.DateTime).Value = beginDate;
cmd.Parameters.Add("@endDate", SqlDbType.DateTime).Value = endDate;
adapter.Fill(ds);
return ds;
}
리스트3. 매개변수를 사용하는 데이터 액세스 코드. 대략 훌륭하다... (자뻑?)
리스트3 코드는 쿼리 내에 @customerID, @beginDate, @endDate 등의 매개변수를 사용하고 Command 객체의 Parameters 컬렉션을 사용하여 매개변수 값을 설정하고 있다. 이 코드가 좋은 이유는 SQL Server가 매개변수가 변경되더라도 이것을 하나의 SQL 문장으로 간주하고 캐시된 실행 계획을 계속 재사용할 수 있도록 해준다는 것이다. 정말로 SQL Server가 SQL 컴파일을 1회만 수행하고 캐시에 저장된 실행 계획을 재사용하는가를 알아보기 위해 리스트1의 코드를 12회 반복 호출하고 리스트3의 코드를 12회 반복 호출하는 코드를 수행 시키면서 성능 모니터에서 SQL 컴파일 회수를 살펴보았다. 결과는 화면1과 같다. 첫 번째 높이 솟아있는 것이 매개변수를 사용하지 않는 리스트1이 수행되었을 때의 초당 SQL 컴파일 회수이며 두 번째 낮게 깔린 봉우리가 매개변수를 사용하는 리스트3이 수행되었을 때의 초당 SQL 컴파일 회수이다. 차이를 느낄 수 있을 것이다.
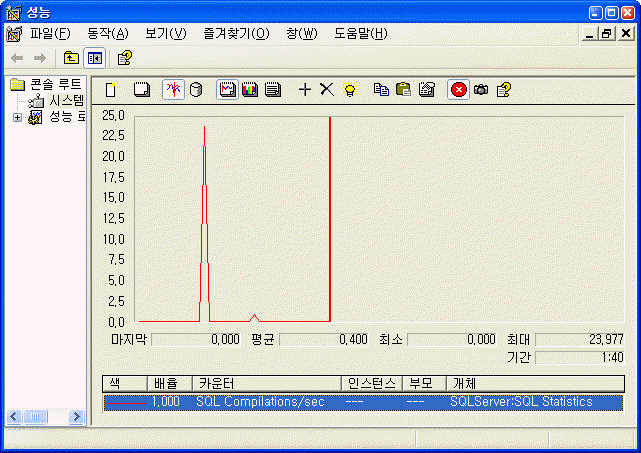
화면1. 매개변수를 사용한 경우와 그렇지 않은 경우 SQL 컴파일 회수 비교
리스트3의 코드가 좋은 코드인 이유는 문자열 연산을 사용하지 않는다는 점이다. 잉? 필자가 말도 안되는 사기를 친다고? 코드를 보면 분명 + 연산자로 문자열을 더하고 있지 않은가? 리스트3의 코드는 보기 좋게 하기 위해 문자열을 쪼갰을 뿐 실제 컴파일된 코드는 단일 문자열을 사용한다. 즉, 문자열 연산이 없다는 말이다. 상세한 내용은 "StringBuilder에 대한 진실 혹은 거짓말" 씨리즈 글을 살펴보기 바란다.
마지막으로 리스트3의 코드가 좋은 이유로는 매개변수의 타입(type)을 nchar 니 DateTime 등으로 명시하고 있다는 것이다. 이 글에서 든 예제는 그렇지 않지만 매개변수를 사용하지 않는 경우나, 매개변수를 사용하더라도 매개변수의 타입을 주지 않는 경우, SQL Server가 형변환을 해야 하는 경우가 발생하곤 한다. 이때 데이터베이스 서버에 부하가 증가하여 CPU 사용율이 올라가게 된다. 가급적 명시적으로 매개변수의 타입을 주는 것이 데이터베이스의 부하를 줄이는 좋은 코딩 습관이 되겠다.
Use Stored Procedure
이야기가 좀 빗나가겠지만, 쿼리를 직접 구사하는 것 보다는 저장 프로시저(Stored Procedure)를 사용하는 것도 좋은 방안이다. 저장 프로시저는 생성과 동시에 컴파일되고 실행 계획이 저장(캐시가 아니다!)되므로 더욱 더 나은 효율을 나타낼 수도 있다. 게가다 저장 프로시저에게 값을 넘겨 주기 위해서는 반드시 매개변수를 써야할 것이며, 저장 프로시저는 달랑 이름만 주게되므로 문자열 연산이니 StringBuilder니 하는 복잡함도 없을 것 아닌가?
저장 프로시저를 쓰는 것에는 이견이 분분하다. 마이크로소프트는 성능 등의 관점에서 저장 프로시저의 사용을 권장하지만, 일선 SI 프로젝트에서 저장 프로시저를 기피하는 경우가 많다. 이유는 관리가 어렵다는 것인데 사실 무분별하게 저장 프로시저를 사용하면 데이터베이스는 온통 저장 프로시저들이 쌓여 있게 되고 어떤 것이 실제 사용 중이고 어떤 것이 수정되면 어떤 영향을 주는지 추적이 안 되는 경우가 많이 발생하곤 하기 때문이다. 필자의 의견은 저장 프로시저가 무분별하게 사용되고 있다는 것은 그만큼 설계가 명확하고 정확히 안되 있다는 말과 동등하다. 설계가 제대로 되어 있고, 문서화만 제대로 되어 있다면 추적이 안 되거나 무분별하게 남용되는 저장 프로시저는 없다고 본다. 사실 우리나라 SI 환경에서 설계를 제대로 하기란 매우 어렵다. 쓰봉... 뻑하면 요구사항이 변경되고(요거 존나 열받는 시츄에이션이다) 화면들이 매우 복잡하기 때문이기도 하지만 설계를 등한시 하는 풍토 때문이기도 하다.
어찌 되었건 저장 프로시저의 사용 여부는 해당 프로젝트에서 성능, 관리 측면에서 충분히 검토하고 신중이 결정하면 될 것이다(오호... 또 슬그머니 빠져나가는... -_-; ).
What about Oracle ?
지금까지 필자가 이야기 한 것은 모두 SQL Server에 대한 내용 이였다. 오라클은 어떨까? 뻑 하면 입버릇 처럼 필자가 이야기 하는 바 대로 필자는 오라클에 대해 조또 아는 것이 없다. 하지만 상식적으로 생각해 봤을 때 둘은 비슷하지 않을까 한다. 고로... 오라클에서도 매개변수를 사용하는 쿼리를 써야 하지 않을까가 필자의 생각이다. 오라클에 대하 잘 아는 사람 있으면 필자에게도 알려주는 은혜를 베풀기 바란다.
Conclusion
데이터 액세스 코드를 작성할 때, SQL 문장을 문자열 연산이나 StringBuilder를 사용하여 작성하는 것은 비효율적인 방법이므로 지양해야 한다. 대신 적극적으로 매개변수를 사용하는 쿼리 문장을 작성하여 사용하는 것이 좋다. 매개변수를 사용하는 쿼리 문장은 SQL 컴파일 회수를 줄여주고 캐시 된 실행 계획을 재사용할 확율을 크게 높여주기 때문이다.
매개변수를 사용하지 않는 쿼리를 쓰면 큰 문제가 생길까? 그에 대한 답은 "글쎄요" 이다. 사실 매개변수를 사용하지 않는 쿼리를 쓰더라도 어플리케이션이 기대하는 만큼의 충분한 성능을 낸다든가, 그렇게 사용하더라도 데이터베이스에 큰 부하가 없이 탱탱거리고 노는 서버라면 굳이 매개변수를 쓰는 쿼리를 반드시 써야만 하는 것은 아니다. 잘 작동하는데 뭐... 글타... 잘 작동하면 장땡인 것이다. 굳이 잘 도는 코드를 바꾸려고 드는 것은 힘이 남아 돌아 주체를 못할 때 해보는 것이 맞는 것이다.
하지만... 버릇이라는 것이 무서운 것이, 다른 코드를 작성할 때 버릇처럼 이전 코드와 동일하게 작성했는데 또 성능상에 문제가 없으리란 법이 없는 것이다. 그래서... 처음부터 권장되는 코딩 패턴으로 코드를 작성하는 버릇을 들여 놓으면 다음에도 그 다음에도 권장되는 코드들을 작성해 나갈 것이 아닌가? 뭐 필자의 말에 동의한다면 이제부터라도 데이터 액세스 코드를 작성할 때 매개변수를 사용하는 코드를 작성하기길 바라며 졸필을 마친다. (웬지 머쪄 보인당... 헤벌레~)
Appendix. Auto-Parameterize
SQL Server 2000에는 자동 매개변수화(Auto-Parameterize) 기능이란 것이 있다. 이 기능은 매개변수를 쓰지 않은 쿼리가 사용되더라도 자동으로 매개변수 사용된 것처럼 실행 계획을 세워두는 것을 말한다. 예를 들어 다음과 같은 쿼리가 수행되면,
SELECT * FROM Northwind.dbo.Products WHERE CategoryID = 1
마지막 WHERE 절에 매개변수가 사용된 것 처럼(WHERE CategoryID = @param1) 실행 계획을 작성해 둔다는 것이다. 그래서 나중에 동일하지만 값이 다른 다음과 같은 쿼리가 수행되더라도 실행 계획을 재사용하도록 하는 기능이다.
SELECT * FROM Northwind.dbo.Products WHERE CategoryID = 4
필자가 본문에서 SQL Server가 상당히 영리하다고 언급한 이유가 바로 여기에 있다. 리스트1의 코드를 매개변수를 달리하여 반복적으로 수행하면 점점 SQL 컴파일 회수가 줄어드는 것을 성능 모니터에서 발견할 수 있다. 컴파일 회수가 줄어드는 이유가 바로 이 자동 매개변수화 기능 덕분인 것이다.
하지만 자동 매개변수화는 항상 성공하는 것은 아니다. 복잡한 쿼리가 사용되는 경우, SQL Server는 자동 매개변수화에 실패하는 경우가 많이 발생되곤 하기 때문이다. 이 때문에 우리는 이 자동 매개변수화에 의존해서는 안 된다. 될 때도 있고 안될 때도 있는 자동 매개변수화에 의존하는 것보단 아쌀하게 매개변수를 명시적으로 사용하는 쿼리를 사용함으로써 안정적인 코드를 유지하는 것이 좋다.
Comments (read-only)
#중간에 오타입니다요. ^^ / 정성태 / 2005-10-28 오전 9:55:00
"마이크로소프트는 성능 등의 관점에서 저장 프로시서의 사용을 권장하지만"
에서... 프로시서.
#수정했습니다... / 블로그쥔장 / 2005-10-28 오전 11:26:00
아우... 꼼꼼도 하셔라... ^^
그만큼 관심이 많으시다는 것으로 알고 이씀니다... 감사합니다...
#re: ADO.NET 코딩 패턴 : Parameterized Query 사용 / 안종윤 / 2006-01-10 오전 12:52:00
정말 도움이 많이 되는 블로그 입니다. 쥔장님이랑 우연히 동템에서 몇번 뵌적은 있는데..
제가 모셨던 이모 과장님(그때 직함) 이 이 블로그를 소개시켜주시더군요. 저같은 개념이 없는 초보에게는 체계적으로 정리를 할 수 있어서 참 많이 도움됩니다.
앞으로 자주 들르겠습니다.
#참고 사항입니다. / 옵져버 / 2006-01-17 오후 4:12:00
문자열 더하기에 비하여 파라미터를 사용하는 방식은 아주 좋은 방식입니다. 물론 저도 이런식으로 많이 사용하구요..
하지만 한가지 주의사항이 있다면, 파라미터의 값이 범위로 작용할 경우.. 게다가 그 범위의 값의 편차가 아주 심할경우.. 역 효과를 낼 수 있습니다.
예를 들어 범위를 주어 검색하는 경우 인덱스 스캔이냐, 풀 스캔이냐 가 틀려질 수 있는데.. 실행계획 캐시로 인하여 제대로된 실행계획을 실행하지 못할 수도 있습니다.
#re: ADO.NET 코딩 패턴 : Parameterized Query 사용 / 블로그쥔장 / 2006-01-17 오후 4:20:00
흠... 그렇다면 값의 편차가 심한 조회가 자주 일어나는 경우엔 저장 프로시저를
사용하는 것도 좋지 못하는 말도 되겠네요...
제가 DB쪽은 무식이 심해서 잘 이해가 안가는데...
인덱스 스캔을 하지 않고 풀 스캔을 한 경우는 해당 쿼리를 고려하지 못하고
인덱스를 잘못 잡아준 경우로 봐야하지 않나요? 인덱스를 적절하게 잡아주는 것이 맞는 방법이지
파라메터를 사용한 것을 문제삼기는 좀 어렵다고 보는데요... (의견 주십시요)
어떤 경우에 파라메터를 사용하면 풀 스캔이 일어나는 등의 역효과가 나타날 수 있는지
저를 비롯한 무식한 중생들을 위해 좀 구체적으로 설명을 해 주심이... -_-;
#참고 사항의 참고 입니다 ^^ / 옵져버 / 2006-01-18 오전 10:14:00
쥔장님 말씀하신대로 스토어드프로시져도 같은 경우에 해당이 됩니다.
그렇기 때문에 DB 튜닝하시는 분들의 조언을 빌리자면 SP 의 경우도 with recompile 명령을 사용하여 경우에 따라서는 매번 실행계획을 다시 세우도록 권장하고 있습니다
(물론 일반적인 경우가 아니라 값의 편차가 심한경우처럼 특별한 경우의 예기 입니다.)
저도 DB 전문가는 아니기 때문에.. 간단하게 예를 들어서 말씀드리면..
읽어야 하는 값이 전체Row의 70 % 데이타를 읽어들인다고 했을때 인덱스를 사용하지 않고 풀 스캔을 하도록 실행계획을 세웁니다.
(검색 범위가 일정 수준을 넘어가면 풀 스캔이 더 효율적입니다)
그러나 5%의 데이타만을 읽어들인다고 했을때는 인덱스를 사용하도록 실행계획을 짭니다.
즉.. 처음 파라미터에 의해서 읽어들여야 하는 데이타가 5% 미만이라고 했을때 인덱스 스캔으로 실행계획을 세웠다가 그 다음 파라미터에 의해서 읽어들여야 하는 데이타가 70%라고 한다면 실행계획이 캐시되어 있기때문에 동일하게 인덱스를 사용해서 데이타를 읽어들인다는 예기죠.. 그럴경우 성능은 풀스캔보다 저하됩니다.
하지만 대부분의 경우 범위를 주어서 조회하는 쿼리라고 하더라도 전체 데이타의 반 이상을 조회하는 경우는 거의 없다고 볼수 있죠..
그래서 단순히 참고사항이라고 밝혔을 뿐입니다. ^^
#re: ADO.NET 코딩 패턴 : Parameterized Query 사용 / 블로그쥔장 / 2006-01-18 오전 10:28:00
그렇군요... 좋은 설명 감사드립니다. 이해가 팍~ 되는 군요...
그렇다고 해서 파라메터를 사용할 것인가 말것인가를 DB 전문가가 아닌 일반 개발자에게 판단하라고
할 수는 없다고 보입니다. 짧은 시간에 많은 코드를 찍어내야 하는 개발자들에게는 무리지요.
쿼리에 파라메터는 항상(?) 사용하고, 대신 쿼리에 사용되는 매개변수의 빈도에 따라서
인덱스를 적절히 잡아주는 것이 더 낫지 않을까요?
예를 들어, 전체 row의 60~70%를 조회하는 경우가 대다수라면 애초 실행계획이 그렇게 잡히도록
인덱스를 잡아주는 거죠. 예외가 발생한다면 그건 소수의 경우이므로 성능상의 손해는 감수 해야 할 것 같은데요...
좋은 커맨트 감사합니다...
아... 어려운 DB의 세상이여... ^^
#re: ADO.NET 코딩 패턴 : Parameterized Query 사용 / 최근한 / 2006-05-07 오전 6:34:00
Stored Procedure(우리는 SP라 부릅니다. ^^;) 를 통해 개발하는것에 대해 너무 부정적이신듯 하여 감히 댓글 하나 남깁니다.
저희는 대부분의 비지니스 로직들을 Stored Procedure를 통해 처리하는데, 나름대로 생산성 및 유지보수에 대해서는 상당히 만족하고 있습니다.
원래 기존에는 SP를 함수 개념으로 사용했었는데, 이게 문제가 장난이 아니라... (문제는 지적하셨다시피 어느것을 수정하였을때 어떤 사이드 이펙트가 발생하는가라는 문제입니다. 몇번 삽질했습니다.)
그래서 SP 를 사용하는 개념을 하나의 업무 로직 / 하나의 화면단위로 분리해버리니, 즉 코드 중복을 감수하고 모든 SP 들간의 의존성을 완전히 제거해버리자, 문제가 모두 해결되는것 같더군요. ^^
(간단히 말해 SP 에서 다른 SP 호출하는 부분을 모두 없엤습니다.)
보통 조회화면은 하나의 SQL로 구현하여 그것을 SP로 짜서 인자를 받아 처리합니다. 로직을 담는 SP들은 한번에 처리되어야하는 JOB 개념으로 한번에 처리해주고요.
말씀하신 것처럼 SP의 관리가 애매한것이 가장 큰 문제인데.... 나름대로 SP 관리툴을 .net으로 만들어보려하는데 한 100년 걸릴것같습니다. 캬캬..
#re: ADO.NET 코딩 패턴 : Parameterized Query 사용 / 블로그쥔장 / 2006-05-07 오후 4:35:00
SP 사용에 대해 부정적이라니요?
전 그런말 한적이 없는데요... 저는 오히려 SP 사용을 권장합니다.
다만... 말씀하신대로 SP가 SP를 호출하는 등의 과도한 SP 사용은 관리를 어렵게 하고
성능상의 문제를 유발할 수 있다는 뜻입니다.
SP는 잘만 사용하면 성능 향상의 지름길이 되지만, 잘못된 용법이나 과도한 사용은 오히려
독이 될 수 있다는 것이지요.
#re: ADO.NET 코딩 패턴 : Parameterized Query 사용 / 고무신 / 2006-07-17 오후 1:14:00
recompile을 방지하기 위해 정적 SP와 파라미터라즈 query를 사용하는 걸로 알고 있습니다. 그만큼 자원이 절약됩니다. ad-hoc query나 동적 query등은 recompile을 유발합니다. 또한 보안상으로 sql injection 등의 문제도 발생할 수 있습니다. 일부러 recompile 옵션을 주는 것도 올바른 방법이 아니라고 봅니다. query optimizer가 알아서 해주는 걸로 알고 있습니다. 아무리 index hint를 주어도 그 index가 허접이면 알아서 무시합니다. sql서버는 또한 통계정보를 알아서 판단해서 일반적을 사람보다 똑똑하게 수행해주는 걸로 알고있습니다. 테스트 해보니 모든 동적 query와 ad-hoc query가 반드시 compile을 유발하는 것은 아니지만 제생각에는 정적 sp와 파라미터라즈 query 어는 것도 문제가 되지는 않다고 봅니다. 대신 비지니스 로직을 어디에다 놓느냐는 개발 방법론을 어떻게 채택하는냐의 문제일 것 같습니다. 저같은 경우는 약간의 성능의 잇점을 위해서 sp에서 어는 정도의 비지니스 로직을 처리하는 것을 선호합니다...잘살자.
#re: ADO.NET 코딩 패턴 : Parameterized Query 사용 / 블로그방문자 / 2006-11-15 오후 6:01:00
굿잡.. 잘봤습니다. 명쾌한 설명 정말 좋습니다.
계속해서 올려주세요.. 열쉬미 보께요..
#re: ADO.NET 코딩 패턴 : Parameterized Query 사용 / 초보방문자 / 2007-04-04 오후 12:52:00
쿼리문 하나, 문자열 하나를 만드는데도 이렇게 오묘한 진리들이 있다니.-_-;;;전 너무 생각없이 만들었던것 같네요...핫...지금부터 반성하고 최대한 효율적인 코딩을 해야겠네요 또한 자주 들러서 나머지 강좌를 봐야겠다는..~~
