이 글은 오래된 전에 작성된 글입니다. 따라서 최신 버전의 기술에 알맞지 않거나 오류를 유발할 수 있습니다.
저자는 이 글에 대한 질문을 받지 않을 것입니다. 하지만 이 글이 리뉴얼 되면 이 글에 대한 질문을 하거나
토론을 할 수도 있습니다.
안녕하세요. 한 6개월 정도 이 핑계 저 핑계 대면서 글도 안 쓰고 게으름 피우다가 요즘에 심기일전하고 이런 저런 내용의 글을 쓰고 있습니다. 이번 내용은 모 개발자 커뮤니티에 올라온 질문에 대한 답변을 쓰면서 심심해서(!!) 정리해 본 내용입니다.
문자(character)는 문자열에 비해 직접적으로 많이 사용되는 타입은 아닙니다. 하지만 가장 기초적인 데이터 타입 중에 하나이므로 소홀히 할 수 없습니다.
Is the Hangul character?
문자 타입(character type)? 문자열이 아닌 문자 타입이라... 그런 타입도 있었나? 라고 생각하는 독자라면 지금 곧바로 마우스에서 손을 떼고 숟가락을 놔야 한다. 문자는 정수와 더불어 가장 기초 중의 기초 데이터 타입이다. 필자가 항상 강조하는 원리와 기초에 딱 맞아 떨어지는 타입 중의 하나라고 할 수 있겠다.
문자 타입은 System.Char 구조체(structure)로서 표현되며 C#에서는 char 라는 기본 타입으로도 표현된다. 일단 구조체라고 했으니 기초가 탄탄한 독자라면 문자 타입이 값 형식(value type)이라는 것을 인지 해야 한다. 즉, 힙에 할당되지 않으며 기본적으로 참조가 아닌 값의 복사에 의해 매개변수 전달이 된다든가 등등...
이런 기본 중의 기본을 이야기하고자 키보드를 잡은 것은 아니다. 매우 기본적이지만 많은 개발자가 간과할 수 있는 것은 닷넷에서 문자 타입은 무조건 16비트 크기를 갖는다는 점이다. 닷넷이 항상 유니코드(UNICODE)를 사용하기 때문이다. 이 때문에 알파벳 'A'도 한글 '가' 도 모두 16비트의 크기를 가짐에 항상 주의하자.
"나랏 말쌈이 양키에 달아, 문자와 서르 사맛디 아니할세..."
프로그래밍을 하다 보면, 주어진 문자가 한글인가 아닌가 판단해야 할 때가 종종 발생하곤 한다. 대개 문자열이 한글로 시작하는지 아닌지 판단해야 하는 경우인데... 닷넷 이전의 C++ 같은 경우, 근본이 ASCII 코드인지라 영문이냐 한글이냐에 따라서 하나의 문자가 8비트(1바이트) 혹은 16비트(2바이트)를 차지할 수 있었고, 문자셋을 어떤 것을 쓰는가에 따라서 주어진 문자가 한글이냐 영문이냐 판단하기가 대략 쥐랄 같았다.
닷넷은 자바와 더불어 문자는 항상 유니코드 문자셋을 사용한다. 따라서 항상 하나의 문자는 16비트의 길이를 갖는다. 그래서 문자열의 첫 번째 문자를 추출할 때 1바이트를 취해야 하는지 2바이트를 취해야 하는지 고민할 필요가 없다.
쓸데 없는 소리는 이젠 그만하고 본론으로 들어가 보자. 문자열이 한글로 시작하는지 영문으로 시작하는지 판단해야 한다고 하면 독자는 어떤 방법을 쓰겠는가?
필자도 문자 타입을 쉽게 생각했다. 유니코드가 라틴계의 영어 문자로서 ASCII 코드를 기반으로 하고, 0 ~ 0xFF 까지가 라틴 문자(영문자 및 기타 문자들)이므로 한글이냐 아니냐를 판단하는데 다음과 같은 간단한 코드 하나면 끝이라고 생각했다.
// 주어진 문자가 한글인가 아닌가를 반환한다.
private bool IsHangul(char c)
{
if (c < '\xff')
return false;
else
return true;
}
리스트1. 잘못된 한글 문자 판단 코드
리스트1에서 생소하게 보일 수 있는 코드에 대해 먼저 언급하자면, 문자 상수는 작은 따옴표(single quote)로 묶어 표현할 수 있고 백 슬래시(\) 문자와 더불어 유니코드 값을 명시할 수 있다는 점(쫌 어려운 말로 escape 문자)이다. 어찌 되었건 리스트1 은 주어진 문자의 코드 값이 0xff 보다 작으면 한글이 아니고 0xff 보다 크면 한글이라 판단하고 있다.
하지만 이 코드는 매우 잘못된 코드이다. euc-kr 이나 ks_c_5601 의 문자셋이라면 리스트1의 코드가 일부 유효하다고 우길 수 있을 지도 모른다. 하지만 유니코드는 euc-kr 이나 ks_c_5601 문자셋과 전혀 다르다. euc-kr 이나 ks_c_5601 문자셋과 그 코드는 영문과 한글 및 기타 한자를 표시하기 위한 문자셋이다. 그래서 영문이 아니면 한글이다라고 우길 수 있는 여지가 조금이나마 있다. 하지만 유니코드 문자셋은 한글, 영문 뿐만 아니라, 라틴계, 러시아, 인도, 왜놈들 글자, 중동의 지렁이 글자들까지 모두 포함하는 매우 포괄적인 문자셋임을 기억할 필요가 있다. 닷넷이 유니코드를 사용한다는 점을 고려해 보면 영문이 아니면 한글이라는 논리의 리스트1 코드는 전혀 설득력이 없게 된다.
"이런 전차로 어린 개발자가 조낸 삽질을 해대니..."
그렇다면 한글인가 아닌가를 판단은 어떻게 해야 하는가? 닷넷에 이런 기능을 제공하는 클래스는 없을까? 필자 또 조낸 MSDN을 뒤졌다. 솔직히 말하면 Reflector로 Char 구조체의 몇몇 메쏘드를 까본 결과 유용한 클래스를 발견했다. 이 클래스가 System.Globalization 네임스페이스의 CharUnicodeInfo 클래스이다. CharUnicodeInfo 클래스는 닷넷 프레임워크 2.0에 추가된 클래스로서 sealed 클래스이자 인스턴스를 생성할 수 없는 클래스이다. 왜 이 클래스가 정적 클래스(static class)가 아닌지 잠시 의아해 했지만 그냥 넘어가기로 하자.(정적 클래스가 뭔지 모른다면 일단 쑛 잡고 30초 정도 반성한 후 C# 2.0 언어의 새로운 기능에서 정적 클래스 찾아 보기 바란다). CharUnicodeInfo 클래스는 달랑 몇 개의 static 메쏘드만을 갖고 있으며, 이 메쏘드들은 주어진 문자가 어떤 종류인가를 반환해 주거나(GetUnicodeCategory 메쏘드) 이 문자가 숫자로 표현할 수 있다면 숫자 값이 얼마인가를 반환해 준다(GetDigitValue, GetNumericValue 등).
잠시 눈이 반짝인 필자, CharUnicodeInfo 클래스의 GetUnicodeCategory 메쏘드는 주어진 문자가 한글인가를 반환해 주지 않을까 기대를 했었다. 결론부터 말하면 아쉽게도 GetUnicodeCategory 메쏘드가 반환하는 UnicodeCategory 열거자(enumeration)는 문자가 숫자인지 괄호인지 대문자인지 소문자인지 등을 알려주지만 그 외의 것은 모두 OtherLetter 라고 반환해 버린다. 즉, 한글이든 한자든, 왜놈 문자든 모두 OtherLetter 문자라는 카테고리에 속해 있다.
이런 줴길슨... 쓰바 만드는 김에 한글인지 한자인지 이런 거까지 구분해 주면 좀 좋아? 그런데 이게 유니코드 표준 3.1을 기반으로 했다니 별 할말도 없다. 이젠 닷넷 프레임워크의 클래스들에 의존할 수 없다.
"내 이를 어엿비 여겨, 코드 쪼가리를 맹그노니..."
그래서 유니코드를 정의하고 있는 http://www.unicode.org 사이트에 달려갔다. 어차피 유니코드란 것이 0x0 부터 0xFFFF 까지를 여러 문자에 대응시켜 놓은 문자셋이므로 한글 문자들이 해당하는 영역이 있을 것이다. 그렇다면 주어진 문자 코드가 한글 영역에 해당한다면 그 문자는 한글이고 그렇지 않다면 한글이 아닐 터...
세상은 만만한 게 하나도 없다. 쓰봉... 유니코드 상에서 한글 코드는 연속적인 영역을 차지하지 않았었고, 한글 초성, 중성, 종성에 대한 판단도 필요했다. 게다가 한글 고어 문자(아래 아 등등)에 대한 판단도 해야 하고, 괄호로 싸인 문자(㈀)나 원 문자(㉠) 역시 한글로 판단해야 할 수도 있었다. 하지만 괄호 문자, 원 문자는 프로그램에 따라 한글로 판단하지 말아야 할 수 있으므로 코드에서 제외했다. 상세한 판단 기준은 http://www.unicode.org 에서 한글 문자에 관련된 유니코드 영역을 살펴보아야 한다. 일단 코드를 보자.
public enum HangulCategory
{
한글아님,
한글완성,
한글자모,
한글초성,
한글중성,
한글종성,
고어자모
}
// UNICODE의 문자 카테고리에 의해 주어진 문자가
// 한글의 어떤 카테고리에 속하는지 반환한다.
private HangulCategory GetHangulCategory(char c)
{
if (c >= '\xAC00' && c <= '\xD7AF') {
return HangulCategory.한글완성;
}
if (c >= '\x3130' && c <= '\x318F') {
return HangulCategory.한글자모;
}
return HangulCategory.한글아님;
}
// 주어진 문자열의 특정 위치의 문자가 한글 카테고리의
// 어디에 속하는지 반환한다.
private HangulCategory GetHangulCategory(string s, int index)
{
return GetHangulCategory(s[index]);
}
// 주어진 문자가 한글인가 아닌가를 반환한다.
// (원 문자, 괄호 문자는 한글이 아닌 것으로 판단한다)
private bool IsHangul(char c)
{
return GetHangulCategory(c) != HangulCategory.한글아님;
}
리스트2. 주어진 문자가 한글인가를 반환하는 코드 조각
리스트2에서 GetHangulCategory 메쏘드는 주어진 문자가 유니코드의 한글 영역에 속하는지 판단한다. 유니코드 0xAC00 부터 0xD7AF 에 해당하는 문자가 완성된 한글을 나타내며, 0x3130 부터 0x318F 에 해당하는 문자는 한글 자모 글자(받침 포함) 영역에 해당한다. 이 외에도 유니코드는 한글 초성, 중성, 종성, 고어 등을 나타낼 수 있는 코드 영역이 있다. 필요하다면 영역을 찾아보고 GetHangulCategory 메쏘드에 살포시 if 문 하나를 낑겨 넣자.
참고로 리스트2의 코드는 빡세게 테스트한 코드가 아니다. 고로 위 코드를 인용하여 사용하고자 하는 독자가 있다면 스스로 테스트를 빡세게 해 보아야 할 것이며, 코드에 문제가 있는 경우 득달같이 이곳에 달려와 필자에게 꼰질러 주기 바란다.
혹은, 위 코드와 달리 닷넷 프레임워크에 이미 한글 문자 판단을 위한 메쏘드를 발견하였거나, 위 코드 보다 더 좋은 방법이 있어도 필자에게 꼰질러 주기 바란다. (혼자만 먹고 살려고 하지 말고 다 같이 나눠 먹자 쫌... -_-;)
"개발자마다 수비 니겨 날로 쑤메 뼌한킈 하고져 할 따라미니라"
위 코드를 이용하여 간단한 테스트 프로그램을 짜 봤다.
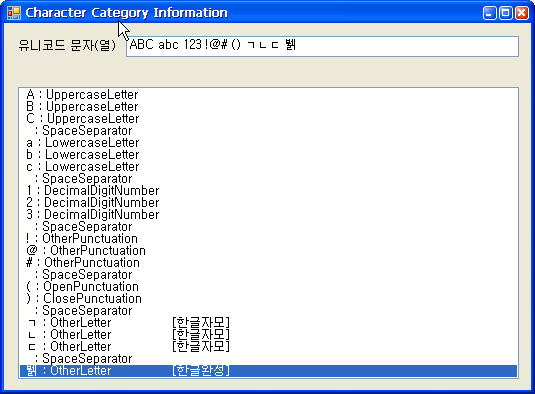
화면1. 예제 프로그램
이 프로그램은 입력된 문자가 CharUnicodeInfo 클래스의 GetUnicodeCategory 메쏘드가 어떤 값을 반환하는가 먼저 보여주고, 리스트2의 GetHangulCategory 메쏘드를 사용하여 한글인 경우 그 종류까지를 보여주는 프로그램이다. 화면1에서 대문자, 소문자, 숫자, 기호, 괄호, 한글 등을 포함하는 문자에 대해 각각의 종류를 보여주고 있다.
위 프로그램의 예제 코드는 물론 없다. 닭이 아닌 이상 이 정도의 정보면 MSDN 디비 보고 짱구 조금만 돌리면 위와 같은 프로그램은 어렵지 않게 작성할 수 있다. 한 두 줄이라도 본인이 직접 코드를 작성해 봐야 그 지식이 나의 것이 된다는 지론에 빠져있는 필자를 설득하려 들지 말지어다.
아놔... 뭐하셈? 얼른 비주얼 스튜디오 띄우고 코드 짜 봐야지 !!!
Comments (read-only)
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / 땡초 / 2006-10-12 오전 1:10:00
오늘의 아티클은 굉장히 재미있게 읽었습니다.
지금은 당장.. 모르겟구요..
샘플은 담에 와서 따라할께요..
넘 피곤한 관계루 ^^;
좋은 아티클 감사합니다.
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / 유치수 / 2006-10-12 오전 10:20:00
출근하자마자 재미있는 글 읽었습니다.
바로 VS 띄워봐야겠네요~
좋은 글 감사합니다~
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / 어흥이 / 2006-10-12 오전 11:55:00
항상 이 문제를 그냥 넘기곤 했는데 이 글을 보고 해답을 찾을 수 있을 것 같네요...
역시 듣던대로 설명도 쿨하게 잘 하시고, 쏙쏙 들어 옵니다...^^
감사합니다.~
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / 위시 / 2006-10-12 오후 2:31:00
오늘도 일단 쑛 잡고 30초 정도 반성하면서 재미있는 아티클 신나게 보고 갑니다.
감사합니다..^^
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / 이준영 / 2006-10-12 오후 5:27:00
덕분에 또 좋은 정보 알았습니다..
좀전에 테스트 해봤슴다...잘 되는데요...
아직 실력이 모자라서 다른 방법은 찾을 생각도 못했지만,
문자열에 대해서는 공부를 많이 했슴다...
그럼, 고생하세요~~
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / 어흥이 / 2006-10-12 오후 7:18:00
헉...저 말고도 '어흥이'란 닉네임을 쓰시는 분이...ㅜㅜ
쥔장께서 이리저리 시간들여서 알아내신 정보를 오늘도 이렇게 간단히 얻어가니
정말 죄송스럽습니다만 일단 알려주시는것이니만치 감사한마음으로...^^
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / 블로그쥔장 / 2006-10-14 오후 9:43:00
정말로 어흥이란 닉네임 쓰시는 분이 두분이시군요 !
어쩐지... ^^
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / 즈믄 / 2006-10-17 오후 1:34:00
ㅋㅋㅋ
훈(개발)민정음.. 압권입니다.. 혼자 입 틀어막고 웃어대니 주위 시선이 따갑군요...ㅋㅋㅋ
역시 잘 보고 갑니다...
좋은 글.. 앞으로도 무쟈게 번창하시길... ^^
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / 플러쉬 / 2006-10-17 오후 2:44:00
SmartClient에 대한 정보를 찾다가 알게된 이곳. 플젝 막바지라 할일도 없고..꾸벅꾸벅 정신못차리다 잠깐 깨어날때마다 이곳으로 온다죠. 좋은 정보 ㅋㅅ~
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / 라기 / 2006-10-19 오후 5:53:00
아... 정말 쉽게 넘어갈 수 있는 주제를 딱 꼬집어 올려놓으셨네요. ^^ 정말 많이 배우고 갑니다. ^^
쥔장님의 문장 표현력은 예술입니다요... 최고!
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / 이경구 / 2006-10-20 오후 5:00:00
string str = "a가bcd";
char[] arrTmp = str.ToCharArray();
for (int k = 0;k < arrTmp.Length;k++)
{
if(Convert.ToInt32(arrTmp[k]) >= 44032 && Convert.ToInt32(arrTmp[k]) <= 55203)
{
//완성형 한글 (가~힣)
}
else
{
//그외
}
}
예전에 허접하게 사용 했던 코드입니다.
C#코드를 찾지 못해서 Java코드를 구해서 바꿨었죠 ...
근데 C#하고 Java하고 많이 비슷하던데요. Class, 함수 명까지 ... ^^
한글 자모까지는 미처 생각 못했었는데...
쥔장님의 좋은 글 항상 잘 보고 있습니다.
글도 잘 남기지 않고서리 몰래 보기만 합니다.
늘 감사~
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / 블로그쥔장 / 2006-10-20 오후 7:22:00
자바도 유니코드를 사용하기 때문이지요.
기본적으로 제 글의 소스 코드는 java와 완벽하게 호환됩니다.
님의 코드에서 44032가 16진수로 0xAC00 이며 이를 escape 문자로 표현하면 '\xAC00' 이지요.
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / 시작인거다. / 2006-10-24 오후 1:43:00
쥔장님의 글을 읽을때 기본, 숏에 손 준비하고 보고 있습니다. ^^
좋은 글 감사합니다.
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / 후니 / 2007-01-12 오후 12:03:00
VB.NET으로 코드를 변환하면 어떻게 되나요?
코드를 변환해서 테스트를 해 봤는데 잘 안 되네요...
소스도 같이 붙여넣습니다.
Private Enum HangulCategory
Not_Hangul
Completed_Hangul
Jamo_Hangul
Chosung_Hangul
Joongsung_Hangul
Jongsung_Hangul
Jamo_Goeo
End Enum
Private Function getHanGulCategory(ByVal c As Char) As HangulCategory
If c >= "\xAC00" And c <= "\xD7AF" Then
Return HangulCategory.Completed_Hangul
End If
If c >= "\x3130" And c <= "\x318F" Then
Return HangulCategory.Jamo_Hangul
End If
Return HangulCategory.Not_Hangul
End Function
Private Function getHanGulCategory(ByVal s As String, ByVal index As Integer) As HangulCategory
Return getHanGulCategory(s.Chars(index))
End Function
Private Function isHangul(ByVal c As Char) As Boolean
Return IIf(getHanGulCategory(c) = HangulCategory.Not_Hangul, False, True)
End Function
Private Sub checkHangul()
Dim aStr As String = "한"
WriteLine(isHangul(aStr))
End Sub
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / 블로그쥔장 / 2007-01-12 오후 9:38:00
VB.NET은 escape sequence 가 없는 것으로 알고 있습니다만...
즉 '\xAc00' 같은 표현을 지원하지 않는다는 거죠. (기억이 가물가물 하네요...)
그래서 getHanGulCategory() 메쏘드는 이렇게 바뀌어야 할 듯 싶습니다.
Private Function getHanGulCategory(...) ...
Dim code As Integer = Ascw(c)
If code >= &HAC00 And code <= &HD7AF Then
return ....
End If
...
...
End Function
VB.Net을 해본지 좀 오래되서... 위 코드가 맞을 지는 모르겠습니다만... 대충은 그렇습니다...
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / 정성균 / 2007-03-07 오후 5:03:00
이제야 제대로 좌악 읽었습니다.
단순하게 처리해서 사용했었는데.... 이리도 깊게 ..... 역쉬....^^
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / ㅡㅡ;찾다가 찾다가 / 2007-07-23 오후 3:53:00
ㅡㅡ; msdn 뒤적거리다가 여기까지 왔네요~
좋은글 감사합니다.
한글 패스워드에 관한 상상, 공상, 매직아이까지 하다가 여기까지 왔네요.
수고하십셔~
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / 김복수 / 2007-09-07 오전 10:18:00
저는 일케 섰는뎅...
근데 이렇게 하면 자음이나,,모음 만 입력하게 되면(ㄱ,ㄴ,ㅏ,ㅕ,ㅇ)
한글이 아닌걸로 나와요...ㅎ
public static bool IsHangul(string input)
{
if (input == null || input.Length == 0) return false;
Regex rx = new Regex(@"[가-힣]");
for (int i = 0; i < input.Length; i++)
{
if (!rx.IsMatch(input.Substring(i, 1))) return false;
}
return true;
}
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / 블로그쥔장 / 2007-09-07 오전 11:14:00
우어... 문자하나가 한글인가를 알기 위해 Regular Expression을 사용하는건
파리 잡는데 105mm 박격포를 쓰는 것과 같습니다. -_-;
Regular Expression은 상당히 무거운 객체이므로 사용할 때는 한 번 더 생각봐야할 녀석이지요.
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / 나원참~ / 2007-10-18 오후 1:33:00
제가 살다 살다 이렇게 잼있는 아티클은 첨봅니다
글쓰신분께 커피한잔이라도 사드리고 싶네요 ^^
잘보고 갑니다 ^^
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / 민경환 / 2008-01-16 오후 4:08:00
비베의 치명적 단점중에 escape식의 표현이 없다는거죠
그래서 단순 무식한 방법으로 해결했습니다. -_-)/
유니코드의 16진수를 역변환해서 대조해서 코드값 알아내서
다시 치환 시켰죠 -_ㅠ
비베는 이넘에 역변환도 쉽지 않아서 일일이 헥사값 대조해서
검증 했는데 잘되더군요
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / 키즈 / 2008-01-31 오전 2:02:00
오 감사합니다. 안그래도 MSB가 1인거는 한글로 잡아서 처리중이었는데
한글 자모가 안잡혀서 고민했더랍니다. 영역이 따로 있었군요.
잭일 양키들 ㅠ_ㅠ
잘 보고 갑니다.
#re: 문자 이야기 : 이 넘의 문자가 한글이야 아니야? / 넘 잘보고가요.^^ / 2008-06-26 오후 8:04:00
방금 홈피가서 찾아봤는데요.
마지막 글자가 '힣' 요 글자네요
그리고 코드로는 xD7A3으로 되어있고요
아무래도 xD7AF영역까지 다 사용하겠쬬(xD7A4~xD7AF까지는 빈공백이것죠)
if (c >= '\xAC00' && c <= '\xD7AF') {
return HangulCategory.한글완성;
}
너무 잘 보고갑니다.^^
